 |
どのような時に使うか
- 2変数間の関連を明らかにしたいとき。
- 2つの変数がともにカテゴリカルな変数のときに使う。連続変数の場合でも値の再割り当てを使ってカテゴリカルな変数にさえ変換すればクロス集計を行うことができる。
- 無作為抽出された標本の場合は、カイ二乗検定を行って検定(標本の状態から言えることが、どのくらいの正確さで母集団においても当てはまるかどうかを統計的に確認すること)する。無作為抽出ではないサンプルの場合は参考程度の指標にしかならない。検定することに意味があるかどうか考えてから分析しましょう。
操作手順
- [分析]→[記述統計]→[クロス集計]へ進む。
- 左側のボックスから、説明変数にあたる変数を「行」ボックスに、被説明変数にあたる変数を「列」ボックスに矢印ボタンを使って入れる。一般的に、属性(性・年齢・居住地域・学歴・職業・・・)にあたる変数は「行」に、行動や意識にあたる変数は「列」に入れる。属性同士の場合は、時間的に先行するもの、理論的に考えて順序が先にくるものを「行」に、後にくるものを「列」に入れる。例えば、性別は年齢に先行するので、性別を「行」に、年齢を「列」に入れる。あるいは学歴は職業に先行するので、学歴を「行」に、職業を「列」に入れる。ただし、居住地ごとの性、年齢構成比がみたいといった場合は、居住地を「行」に、性別や年齢を「列」に入れるので、目的に応じて判断すること。「○○ごとの××をみる」といった場合は○○にあたる変数を「行」に、××にあたる変数を「列」に入れると考えておいて良い。
下の例は、性別を「行」に、部活・サークルへの所属を「列」に入れている。なお行・列とも複数の変数を指定できる。たとえば、性別や学年、きょうだい関係を「行」に入れて、被説明変数を「列」に入れれば一括して属性との関連を集計できる。
- 「セル」ボタンを押す。
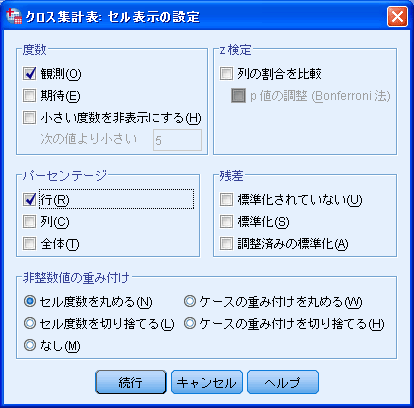
「パーセンテージ」欄にある「行」にチェックを入れる。これをしないと、SPSSは単純に度数だけのクロス集計を出力する。なおここで「行」にチェックを入れる意味は、「行」に入れた変数の合計を100%として、列側の変数の各選択肢にどのような分布をしているかを計算するという意味。[続行]を押して1ページ目のウィンドウに戻る。
*カイ二乗検定
- カイ二乗検定を行わない場合は、このまま[OK]を押してクロス集計を実行する。
- カイ二乗検定を行う時は、1ページ目のウィンドウのなかの[統計量]を押す。
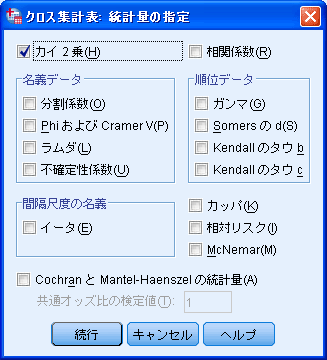
「カイ二乗」にチェックを入れたら[続行]を押して元のウィンドウに戻り[OK]を押して実行する。
出力の見方
- SPSSの出力ウィンドウに以下のような集計結果が表示される(カイ二乗検定は実行時のみ)。これは、年齢と生活満足感のクロス集計を行った例。
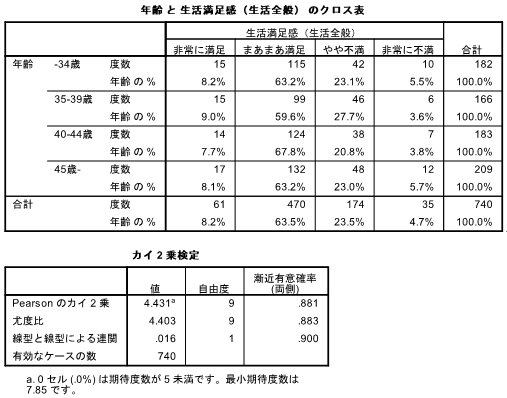
この例では、カイ二乗分析の結果、有意確率が0,05を大きく上回っている(0.881)ので、有意ではない。すなわち、年齢と生活満足感は、標本では上のように年齢によって生活満足感にややばらつきが見られるものの、母集団においてはほとんど関連していない。もし有意確率が0,05を下回っていたならば、年齢と生活満足感は有意に関連しているということになる。このように、データのうえで(標本において)関連があるかどうかと、母集団において関連があると推定できるかどうかは別次元の話なので、統計的検定を行う際は両者を区別して記述しなければならない。いずれにしても、まずクロス集計の結果についてその内容を記述したうえで、「この2変数についてカイ二乗検定を行った結果・・・」と検定の話に進めていく。この辺については「社会統計学」の内容を復習すること。
カイ二乗検定はどのような時に使うか
- 統計的検定とは、「無作為抽出によって得られた標本における状態(2変数間の関連など)が、抽出元の母集団においてもそうであるかどうかを確認する作業」のこと。例えば、神戸市東灘区に居住する20〜69歳の男女から1,000人を無作為抽出してえられた標本において、クロス集計を行ったところ、性別と生活満足度に関連がみられたとして、その関連が母集団においても存在すると言ってよいかどうかを検討することを指す。
- 検定の結果が「有意」でなければ、標本のクロス集計では関連があったとしても、それはたまたま選んだ標本がそうであっただけで、母集団においては関連がないと結論付けることになる。逆に、検定の結果が「有意」であれば、性別と生活満足度は標本だけではなく母集団においても関連している可能性が極めて高いと言うことができる。
- 有意かどうかは、SPSSの出力における「有意確率」から判断する。有意水準の一般的な基準は0.05(5%)。分析の結果において有意確率が5%以上であれば関連は無いと判断する。逆に、5%未満であれば、関連はある(=「5%水準で有意な関連がある」と表現する)と判断する。
- カイ二乗検定に限らず、分析している標本が無作為抽出ではない(=有意抽出)場合は、統計的検定にあまり意味はない(回帰分析など自動的に検定が行われるものについては、論文に掲載してもかまわないが、有意だった独立変数の効果が他の変数よりも強い、程度の意味でとらえるべきだろう)。統計的検定を行って母集団の推定ができるのは、標本の選び方が無作為抽出である場合のみ。この点に注意すること。なんでも検定すれば良いということではない。なお、「適当に選んだ」という方法は無作為抽出ではない(ゼミ論や卒論で行うアンケート調査はほとんどが無作為抽出ではない)。社会調査法の教科書をよく読んで自分の分析している標本がどのような方法で選ばれたと言えるのかを考えておくこと(論文では必ずどのような方法で標本を抽出したかを説明しなければならない)。対象者の属性だけ決めてあとは協力してくれる人を探して頼んだ、あるいは自分の分析枠組みに合致する授業を選んで授業時に配布・回収したのであれば、素直にそのプロセスを書けばよい。JGSSなど2次データの場合は、標本抽出についての解説がウェブサイトやコードブックにあるので論文ではそこから引用して説明すること。簡単に説明したうえで「注1:データ収集の詳細は○○(xxxx)に詳しい。」という文献に関する注釈を付けても良い。
論文におけるクロス集計の記載方法
- 本文中にSPSSの出力結果をそのままコピー&ペーストすることのないように。
- 最低限、以下の例くらいまではエクセルで整形すること。整形するために、SPSSの出力結果をエクセルで編集する際は、SPSS出力ウィンドウで編集するクロス表を選択してコピーし、エクセル上で[形式を選択して貼り付け]→[テキスト]を選択する。整形し終わった表をワード文書にコピーする際は、エクセル上でクロス表を選択して、ワード上で[形式を選択して貼り付け]→[図(拡張メタファイル)]を選択する。
- 論文は内容とともに「見た目」も大事。表のなかの文字が切れていたり、不要な罫線が引いてあったり、フォントがバラバラだったり・・・といったミスをしないよう時間をかけて丁寧に作表すること。
表1 年齢と生活満足感のクロス集計
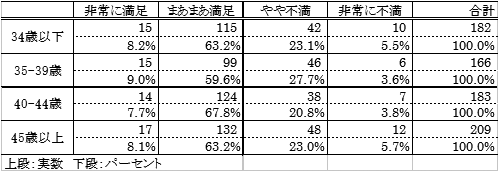
この例では、エクセル全体のフォントの大きさを11ポイントから10ポイントに変更し、フォントは文字部分は「MS P明朝」、数字部分は「Century」を使用している。生活満足感の選択肢が収まるようにセルの幅を10.00に変更し、年齢の部分は「セルを結合して中央揃え」で整形した。選択肢の下のみ二重罫線として、後は罫線でセルを区切り、実数とパーセントの間は、右クリック→「セルの書式設定」→「罫線」へ進んで点線を選択している。表のタイトルはエクセルではなくワードファイル上に書き込んだ。
カイ二乗検定の結果を記載する場合は、「上段:実数 下段:パーセント」の下に、「χ2=0,881, p≧0.05」と入れておく。5%水準で有意だった場合は有意水準の部分を「p<0.05」とする。
実践的なメモ
- クロス表のなかの1つのマス目のことを「セル」という。このセルに入っている度数(人数)が、5未満のセルが多い場合は、「他の変数への値の再割り当て」を行ってカテゴリの数を少なくしてから再度クロス集計を行うこと。草稿チェックの段階で指摘されること無いように!
- 経験的には、3〜5カテゴリ程度の変数であれば集計しても問題ないが、それ以上であれば、カテゴリ数を少なくしたほうがよい。ただし、カテゴリ数を少なくし過ぎて意味のない変数を作ることは時間の無駄。常に仮説のことを頭において、どうのように集計したら仮説の成否を確認できるか考えること。
|
|